


Opdracht: Bouw een voorspellend model
Doel van de opdracht:
Bij deze opdracht ga je aan de slag met het verkennen van de mogelijkheden van machine learning en het toepassen van neurale netwerken.
Hiermee kun je op basis van historische data bijvoorbeeld voorspellingen doen over het mogelijke vertrek van medewerkers, maar kun je ook verkennen welke factoren zoals beloningsmodellen of loopbaanpaden van invloed zijn op vertrek.
Wat ga je doen? Voorspel welke medewerker uit dienst gaat
Je gaat een model trainen dat mogelijk vertrek van een medewerker kan voorspellen en inzicht kan geven in reden voor vertrek.
De basis is een dataset met historische data van medewerkers, met daarin informatie zoals Rol, Dienstjaren, Salaris etc.
We gaan een model maken dat het veld "Attrition (Yes/No)" kan gaan voorspellen, en een exploratie doen van welke factoren vooral van invloed zijn op vertrek (Attrition = Yes)

Je gaat aan de slag met een online omgeving van Microsoft waar je met behulp van machine learning een voorspelmodel kunt maken en data kunt verkennen en analyseren.
Uitleg en Instructies
- 1 persoon uit de groep deelt zijn/haar scherm en gaat naar de volgende website: https://studio.azureml.net
- Login (via de knop 'Sign-in') met MediaPerspectivesTraining@outlook.com en wachtwoord: AI_Training13!
Let op: zorg dat je met bovenstaand account inlogt en niet met je zakelijke of privé Microsoft account!! Als dat wel gebeurt, dan uitloggen en opnieuw inloggen. - De overige personen uit de groep lezen de onderstaande instructies vanaf hun laptop en checken of de persoon die is ingelogd in Azure de juiste stappen zet.
Start een nieuw experiment
Het model dat we gaan trainen gaat gebruik maken van een neuraal netwerk om de waarde voor "Attrition" te voorspellen. Dus de kans of een medewerker wel of niet zal gaan vertrekken.
De basis
- Klik op het menu item "Experiments", klik onderin op "New" en kies het template "Blank Experiment".
- Na het selecteren van het lege template opent een leeg canvas waar we in gaan werken.
Je ziet links een deel waar we items en functies kunnen vinden (zoals onze dataset en het type model dat we straks willen toepassen).
Via drag en drop kun je items op het canvas slepen. We maken het model dus zonder te moeten programmeren of de vaardigheden van een data scientist te hebben.
De opzet
De bedoeling is dat je een eigen neuraal netwerk gaat trainen op onze dataset. Daarvoor gaan we globaal het volgende doen.
LET OP: Verderop staan stap voor de stap de instructies uitgeschreven die je kunt volgen, dit is alleen een globaal overzicht van de stappen!

- De dataset op het canvas slepen
- De dataset splitsen in een trainings-set en een validatie-set
Een voorspel model heeft altijd 2 sets nodig, de data in de trainings-set gebruikt het om te leren voorspellen, de data in de validatie set om te testen wat de kwaliteit van de voorspelling is. - Het algoritme kiezen waarmee we willen gaan voorspellen. In dit geval willen we voorspellen of iemand wel of niet gaat vertrekken. We kiezen hiervoor een neuraal netwerk dat 2 waardes kan voorspellen (in ons voorbeeld Yes of No)
- Vervolgens trainen we het model en kunnen we kijken wat de kwaliteit van het model is.
- Als extra gaan we nog kijken wat de belangrijkste voorspellende factoren zijn voor vertrek. Zowel volgens de data, als volgens het neurale netwerk.
Het eindresultaat ziet er ongeveer zo uit als de afbeelding hiernaast
Aan de slag

We starten met het selecteren en plaatsen van onze dataset.
Sleep onze dataset vanuit 'Saved Datasets > My Datasets' op het canvas.

We gaan nu de data splitsen in een training en een validatie set.
Dat doen we met de functie 'Split Data'
Zoek deze in het panel en sleep het op het canvas onder de het blokje van de dataset.

Verbind nu de twee blokken door op het kleine cirkeltje van het bovenste blok te klikken en de pijl te verbinden met het cirkeltje van het onderste blok

Sleep nu op dezelfde manier de volgende blokken op het canvas.
- Train Model (klik in de linker kolom op ''Train'')
- Score Model (klik in de linker kolom op ''Score'')
- Evaluate Model (klik in de linker kolom op ''Evaluate'')
Verbind ze met elkaar op de wijze zoals in het screenshot hiernaast.
De data zal deze stappen doorlopen van boven naar beneden. Waarbij in de stap 'Train Model' het model gemaakt wordt.
In 'Score Model' en 'Evaluate Model' kunnen we gaan bekijken wat de kwaliteit van het model is.


Nu ontbreekt nog het algoritme dat we willen gaan gebruiken.
We willen een neuraal netwerk gebruiken om te gaan voorspellen.
Zoek in het panel naar het model 'Two-Class Neural Network'
Dit type model kan 2 klasses/waardes gaan voorspellen en is dus nuttig voor onze voorspellen 'Yes' en 'No'
Sleep het op het canvas, net boven 'Train Model'
En verbind het met 'Train Model' zodat het er uitziet zoals in het screenshot hiernaast.
Het model trainen en bekijken
We kunnen nu aangeven wat we het model willen laten voorspellen en het starten.
Om aan te geven welke waarde het model moet gaan voorspellen, selecteer je het blokje 'Train Model'. Vervolgens klik je in het panel aan de rechterkant op 'Launch column selector'.

Hier kiezen we de kolom 'Attrition Yes/No' (door te zoeken in het veld 'Column Names') en vervolgens klik je op het Vinkje om dit te bevestigen.
Hiermee geven we aan dat we het model willen leren de waarde voor 'Attrition Yes/No' te voorspellen

We kunnen nu het experiment een naam geven (klik bovenin op de tekst 'Experiment Created on ...' en vul een eigen naam in zodat je het kunt herkennen.
Druk vervolgens onderin op 'Save' om het experiment te bewaren.
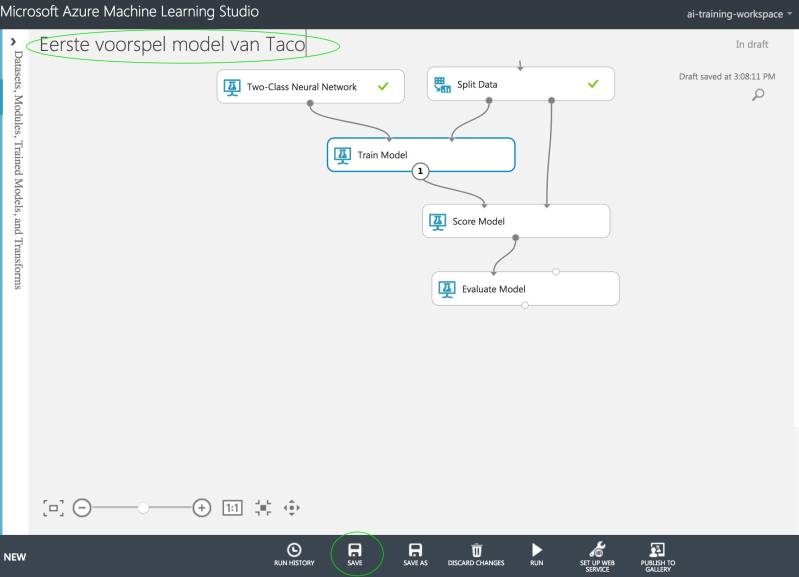
Nu kunnen we het model gaan genereren door op 'Run' te drukken en even te wachten tot alle vinkjes groen zijn.
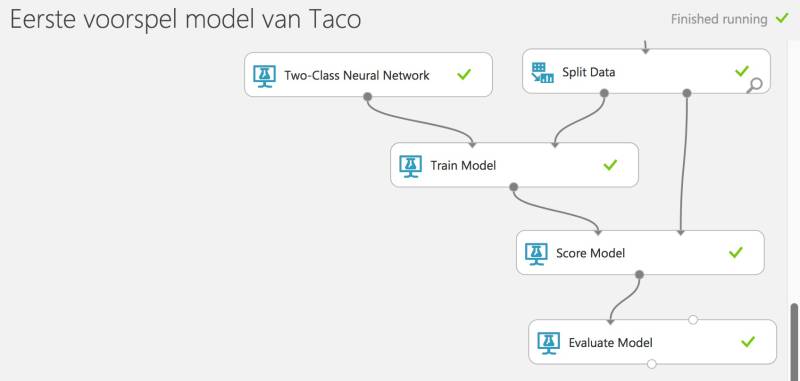
Gefeliciteerd... Je hebt zojuist je (wellicht eerste) voorspelmodel gemaakt op basis van een neuraal netwerk!
Je kunt het model later gaan gebruiken om voorspellingen te doen op nieuwe data, dus bijvoorbeeld voor nieuwe medewerkers. Of je kun je kunt het model gebruiken om regelmatig het mogelijke vertrek van bestaand medewerkers opnieuw te voorspellen. Daarvoor moet je het model publiceren, maar dat gaat voor deze training te ver.
Je kunt wel de blokjes 'Score Model' en 'Evaluate Model' verkennen, en de uitkomsten visualiseren door op een blokje met de rechtermuisknop het menu op te roepen.
Pauze!
Verdieping
Wat leuk is om te achterhalen is welke factoren nou de belangrijkste redenen voor vertrek zijn volgens het model.
Hiervoor bestaan 2 items die op basis van de data of op basis van het getrainde model kunnen aangeven wat de belangrijkste voorspellende factoren (features) zijn.
Ga naar de linker kolom en klik op ''Feature Selection''. Sleep vervolgens 'Permutation Feature Importance' en 'Filter Based Feature Selection' op het canvas, en verbind ze op onderstaande wijze.
Geef bij het blokje 'Filter Based Feature Selection' weer het veld 'Attrition Yes/No' op dat we willen voorspellen zoals je eerder gedaan hebt (via 'Launch Column Selector')

Klik hierna op 'Save' en op 'Run' en wacht tot alle vinkjes groen zijn.
Je kunt nu per blokje de resultaten bekijken, door er met je rechtermuisknop op te klikken en via het menu de resultaten te visualiseren. Zie onderstaande schermvoorbeelden.

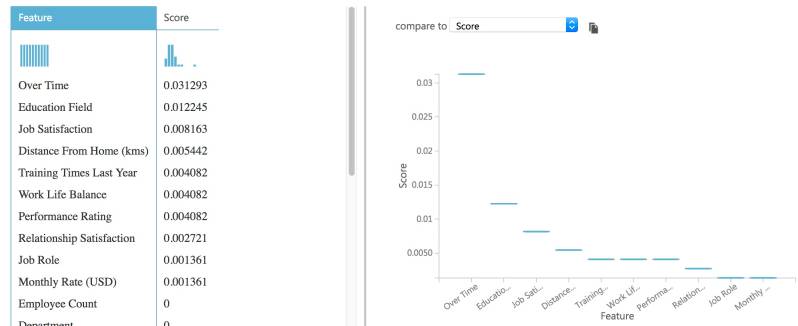

Je ziet dat beide analyses andere voorspellende factoren opleveren, namelijk:
Over Time, Education Field en Job Satisfaction
versus
Total Working Years, Job Level en Years in Current Role
De eerste combinatie is gebaseerd op ons model (dus op basis van een neuraal netwerk), de tweede op een statische analyse van onze dataset.
Het gaat te ver om dit verder uit te leggen, maar de eerste combinatie zou realistischer moeten zijn (de statistische methode geeft namelijk correlatie aan maar dat betekent niet dat er automatisch een causaal verband is, en de permutatie methode op basis van het model kijkt uitgebreider naar de input waardes)
Ok leuk... en wat nu?
Je hebt nu kennis gemaakt met een hele simpele introductie van hoe je een neuraal netwerk kunt trainen met historische data, hoe je mogelijk vertrek van een medewerker kunt voorspellen en kunt achterhalen wat de belangrijkste factoren voor vertrek zijn.
En je kunt bij de koffieautomaat zeggen dat je een neuraal netwerk hebt getraind, en een data scientist vragen waarom hij niet de 'Permutation Feature Importance' functie gebruikt in zijn data-analyses :)
In een echte situatie zul je wel meer data gebruiken en ook een combinatie van meerdere voorspellende modellen gaan toepassen (het stapelen van modellen) om uiteindelijk een goed voorspellend model te krijgen. Er zijn echter ook oplossingen die dit automatisch doen (Automatische machine learning, soort van een machine die een machine traint)
Deze introductie geeft je wel de mogelijkheid om na te denken over toepassingen met historische data
Wat andere bedrijven zoal doen geeft wellicht ook nog extra ideeën.
Wat doen andere bedrijven met deze technologie?
- Voorspellen...
- Je kunt allerlei zaken gaan voorspellen met deze technologie naast vertrek misschien de juiste salarisverhoging om voortrek te voorkomen, of misschien de volgende passende functie of rol voor een medewerker.
Om over na te denken
Hoe zou je deze technologie, mogelijkheden en ideeën in kunnen zetten in jouw dagelijkse werkzaamheden of voor jouw klanten? Welke data is er beschikbaar, kun je combinaties van data verzinnen, en wat zou je kunnen gaan voorspellen?
Maak jouw eigen website met JouwWeb